Messy data.
Plain English.
Done.
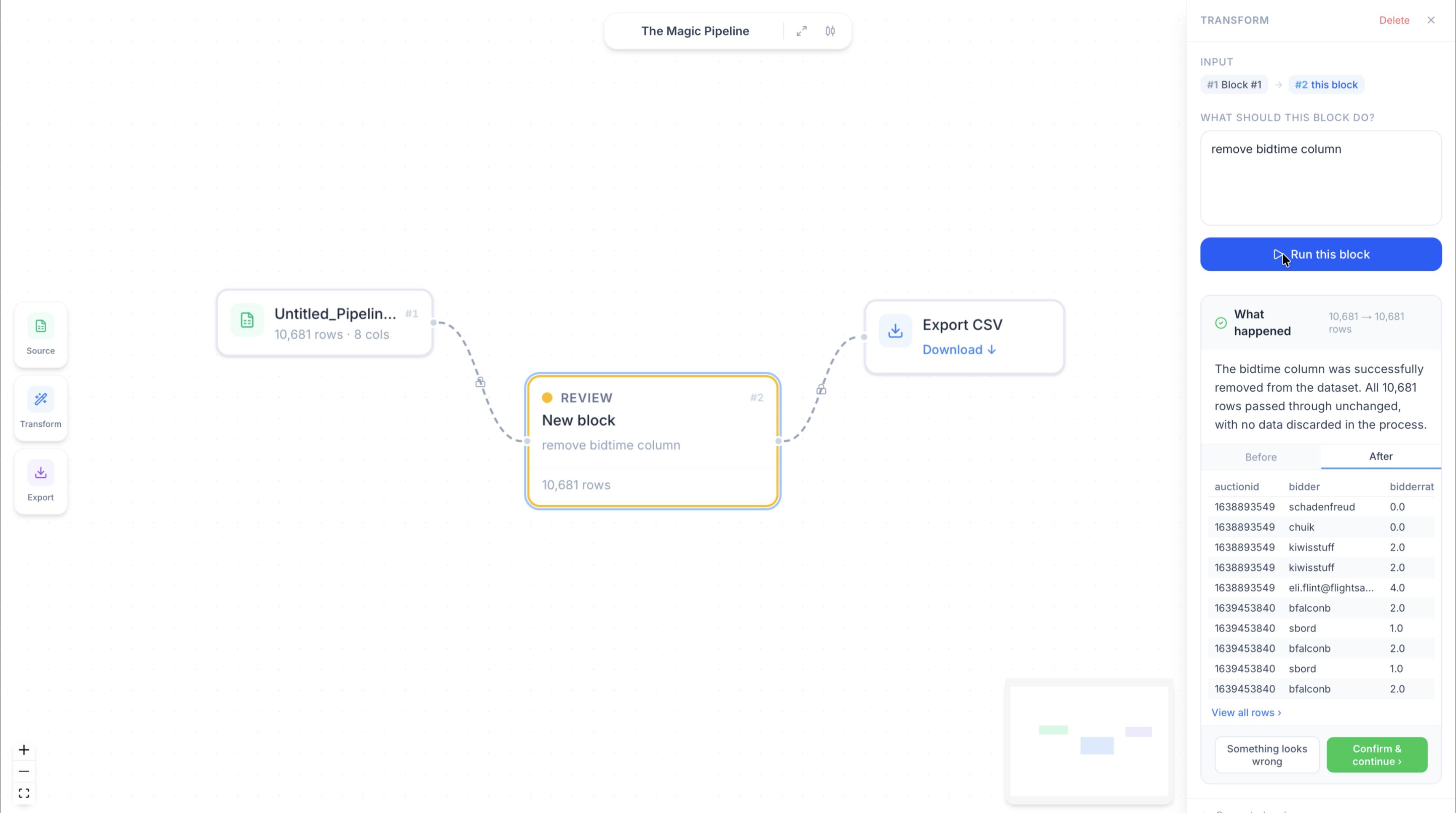
Describe the transformation. The agent writes the code, runs it, and tells you exactly what changed — before anything moves forward.
49,157 rows remain. Email column: all lowercase.
Data work is broken
at the tooling layer.
This isn't a skills problem.
It's a tooling problem.
The work hasn't changed. The tools haven't either.
This is what
tooling catching up looks like.
Drop a file. Describe what you want. Confirm what changed. Repeat.
Three steps.
Every time.
Drop a file. Add a Transform block. Write what you want in plain English.
The agent reads your data, writes pandas code, runs it in a sandbox. Retries on failure.
A card shows what changed. Confirm or describe what's wrong. The agent corrects and reruns.
When something's wrong, you describe it. "Flag them instead of removing." The agent rewrites, reruns, shows you the result.
The agent learns
your data.
Every correction compounds.
In six months, Datumm remembers every rule. In a year, it applies them before you ask.
Here's where
Datumm is right now.
- CSV and Excel files
- Python (pandas) code generation
- Isolated sandbox execution
- Plain-English validation cards
- Step-by-step confirmation flow
- Team workspaces
- Database connectors
- Scheduled pipelines
- Cloud integrations
If you have a messy file and you know what you want it to look like, Datumm handles that.
We're building this in public. If you join the waitlist, you're not waiting for a finished product. You're shaping one.
Join the waitlist.
Shape what's built next.
Early access is free. First users get direct input on the roadmap.
No spam. No sales calls. Direct line to the founders.